
向量搜索前沿调研
Milvus 提供支持
Milvus 是一个开源的向量检索中间件,支持常见的向量检索场景,具备以下特点:
支持基于 Python / Java / Go / C++ 的 SDK 和 RESTful API
支持 Annoy、Faiss、HNSW 等多种算法库
支持 CPU 和 GPU 运算
以 collection 为基本的管理单元,在 collection 中再划分 partition 为基准,支持粗粒度与细粒度的数据管理
支持原始向量存储与查询
近似最近邻(ANN)向量搜索:有用过谷歌的 Vertex AI 向量搜索, 也试过用Apache Solr 的 ANN 向量搜索处理一些大数据集,还有在垂直扩展的边缘节点里部署 Facebook 的 FAISS 库,专门应对小数据集。
性能:月活11亿的Reddit ,怎么选向量数据库:Pgvector、Redis、Milvus、Qdrant
Reddit的案例主要讲了选向量数据库从需求到评估到测试到选用的全过程:
需求:
功能需求?向量和关键词搜索,标签检索,按非向量属性过滤
非功能需求?存 10 亿级向量,P99 延迟能不能控制在 100 毫秒以内
团队需求?不要因为现有方案被带偏需求
评估:
对技术维度权重打分:
纯向量检索产品:Milvus、Qdrant、Weaviate、OpenSearch、Vespa、Pinecone
带有向量检索能力的其他数据库:Pgvector(本来就用 PostgreSQL 当关系型数据库)、Redis(本来就用它做键值存储和缓存)Cassandra(已用于非 ANN 搜索)Solr(本来用它做词法搜索,之前试过用它做向量搜索)、Vertex AI(已经在用来做 ANN 向量搜索)
向量检索数据库的技术维度:
- Search Type (搜索类型): 包括混合搜索(Hybrid Search)、关键词搜索、近似最近邻搜索(ANN)、范围搜索等。
- ==Indexing Method (索引方法)==: 是否支持 HNSW(一种高效的索引算法)、量化(Quantization)、LSH 等。[[索引]]
- Data (数据处理): 支持的向量类型、==元数据==过滤(Metadata filtering)、数据类型多样性等。
- Scale ==(规模与扩展性)==: 能否处理十亿级向量、P99 延迟表现、高可用性等。
- Storage Operations (存储运维): 是否支持 AWS 托管、多区域(Multi-Region)、零停机升级等。
- APIs/Libraries (开发接口): 是否支持 gRPC、RESTful API,以及 Python、Go、Java 等语言库的支持情况。
- Runtime Operations (运行时运维): 包括监控(Prometheus Metrics)、备份/快照(Backups/Snapshots)、Kubernetes Operator 支持等。
- Support/Community (==社区==与支持): 供应商中立性、文档质量、GitHub Stars(受欢迎程度)、社区活跃度。
- Cost & Performance (成本与性能): 性价比、资源利用率调优、分片(Sharding)、自动故障转移(Automatic Failover)、GPU 支持等。
Qdrant 和 Milvus 的架构差异也很有意思,可以对比:
- Qdrant:同构节点架构,一个节点就承担 ANN 向量数据库的所有操作
- Milvus:异构节点架构,查询、索引、数据写入、代理这些功能,都由不同的节点来做
微服务(读写分离,故障隔离可观测性强组件职责单一,同构导致写入阻塞 查询),分布式架构(多副本,无限水平延伸),索引实现机制(前置过滤后置过滤,标量索引和向量索引结合的是否紧密,在构建索引的时候就考虑过滤条件)
定量测试
哪种方案部署起来简单(看文档好不好用)?哪种方案运行起来省心(看弹性和成熟度)?哪种方案在我们关注的场景和规模下性能更好?
- 收集了三个不同使用场景的文档和查询向量数据集
- 在 Kubernetes 里给每个方案分配了差不多的资源
- 把文档数据导入每个方案
- 用 Grafana 的 K6 工具发相同的查询负载:先让系统预热,再升到目标吞吐量(比如 100 QPS)
测试重点看这些: - 吞吐量:找到每个方案的性能临界点
- 吞吐量和延迟的关系
- 负载期间节点挂了之后的表现(错误率、延迟变化等)
- 过滤功能对延迟的影响
另外,我们还做了些简单的 “能用 / 不能用” 测试,验证文档里说的功能是不是真的能用(比如更新插入、删除、按 ID 查询、用户管理这些),同时感受一下这些 API 好不好用。
功能:如何用Milvus一套系统搞定千万用户视频检索关键词
场景:语义搜索视频无法满足剪辑 需求
需求
功能
- 关键词精准检索。
- 双模式切换
- 智能排序
非功能
- 运维成本可控:作为初创企业,需避免因功能升级引入多套搜索系统,控制运营负担与系统复杂性。
- 性能稳定:新增功能后,系统查询响应速度、匹配准确率需满足生产环境要求,大规模文本数据集场景下仍保持高效运行。
- 扩展性良好:支持后续语义搜索与精确匹配的融合查询开发,预留技术扩展空间。
设计
说了 一通milvus优点,解决了他的问题
单一数据库系统同时支持语义搜索与精确匹配,简化运维架构,降低扩展成本;先过滤后排序逻辑兼顾精准性与相关性,提升用户体验。
关键设计要点:
function{
name: ‘text_bm25_embedding’,
type: FunctionType.BM25, // Milvus 自己知道怎么算 BM25
input_field_names: [‘text’],
output_field_names: [‘sparse_vector’]
}
不再需要在客户端自己算 BM25 了。 你直接把原始文本扔给 Milvus,Milvus 内部会自动把它转化成稀疏向量并建立索引。Milvus 在这里既充当了数据库,又充当了分词和向量化引擎。
1 | await this.milvusClient.search({ |
效果
教训
- 内存优化:稀疏索引占用内存较高,大规模文本数据集场景下需启用MMAP(内存映射文件)利用磁盘存储,同时保障足够I/O带宽维持性能。配置方式:在Milvus配置中设置use_mmap: true。
从8万+数据源提炼洞察,ChatGPT+Zilliz +LangChain如何成创新药研发新范式
是啥:TrialHub 则采用了 LangChain + ChatGPT API+Zilliz Cloud的模式进行RAG搭建。Embedding模型,则采用基于 BERT 微调的医学专用模型,生成的embedding数据,则会存储在 Zilliz Cloud 中用于高速、精准的检索。
需求:
高质量搜索
微调了embedding模型,专门用于各种医学术语的表示。
向量数据库需要满足以下特征:能够处理数十亿个向量、具备商业级的系统可靠性、能够同时处理结构化信息,以及PDF在内格式复杂的非结构化内容。
所以用milvus
快看
需求
向量检索,智能问答
向量检索的实现没什么说的,L2欧式距离检索+HNSW索引
下面是只能问答的技术设计
设计
- 数据收集:问答;结构化数据表([[数据处理]])
数据清洗
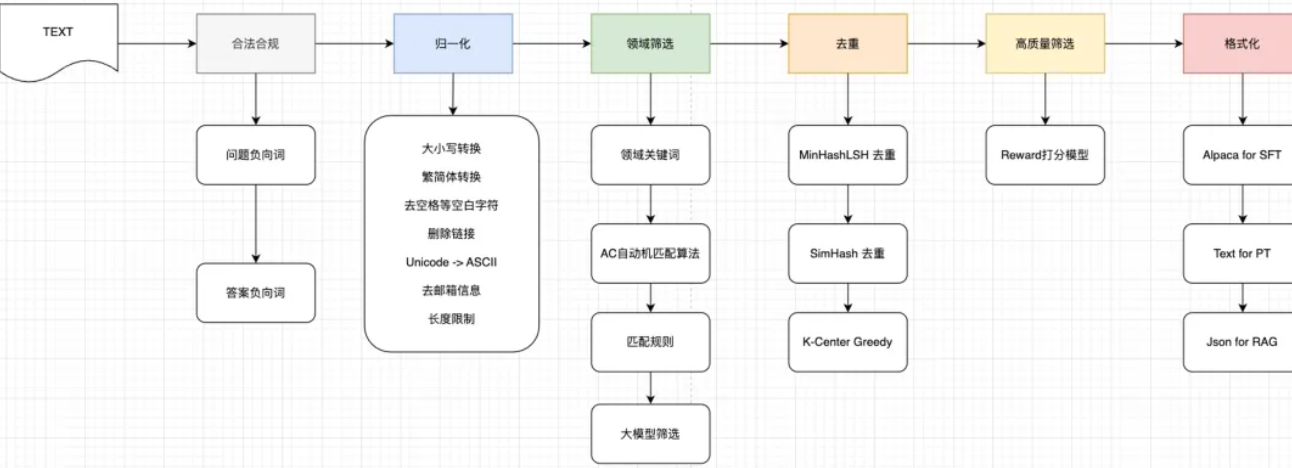
- Embedding:自己在业务数据上训练Embedding模型,Embedding模型在doc上编码出向量,L2归一化后存储到Milvus中。
- 索引:通过milvus的API,创建collection集合&对向量字段构建index索引,入库到milvus 索引:HNSW。除了Embedding的 dense索引,我们还会基于ES在每个知识库上构建倒排索引。
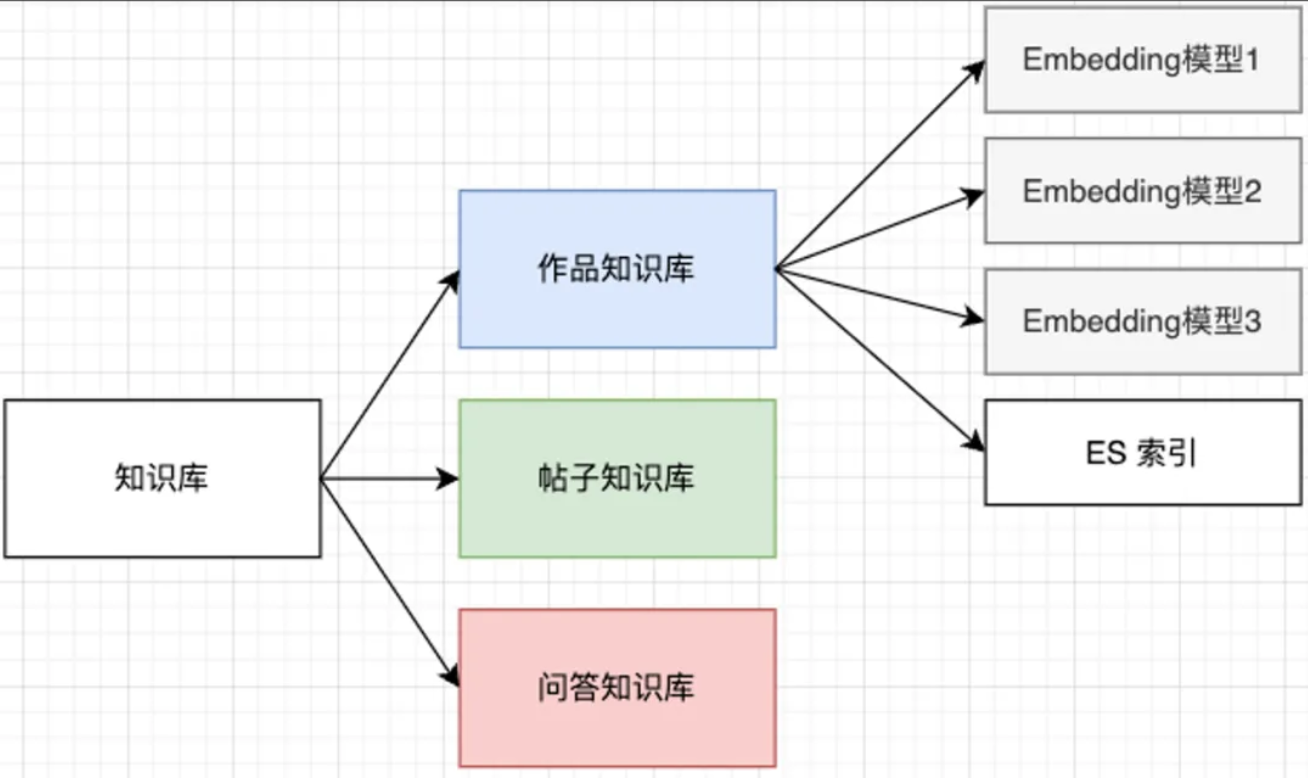
- 向量查询:[[检索]]
目前的混合策略是先进行ES前置检索,返回父层级的索引,然后在这些父索引范围内,进行更精确的doc层级的向量索引。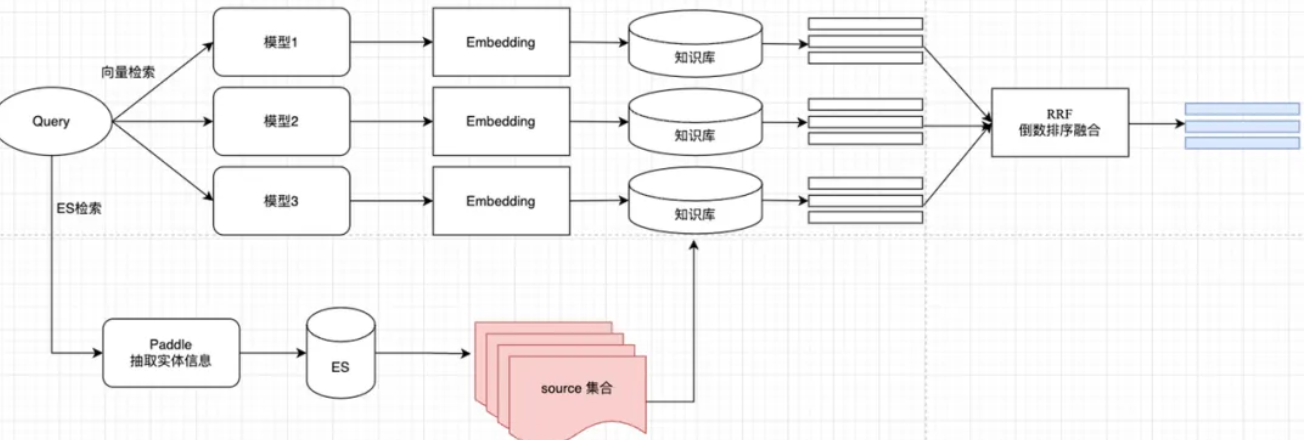
- 重排:Cross-Encoder架构。
重排之后,并不会把top3 doc丢到大语言模型里进行生成,因为这top3 doc,我们看作是3个定位锚点,接下来会以每个锚点为中心进行上下文扩展,增强背景信息,但是在扩展的过程中要注意几个细节,比如docId对齐、doc去重、扩展边界、doc还原顺序等等。扩展后的内容会合并成一个context,丢到大语言模型中进行生成。 - 评估:召回率评估,ragas端到端评估(不推荐需要考虑双重稳定性和置信度的问题,标答消耗人力,字数变化表达方式变化都会影响评测指标)
为了解决更复杂的业务case,我们做了一些改造,包括query转换、检索时机意图识别、Text2SQL
使用
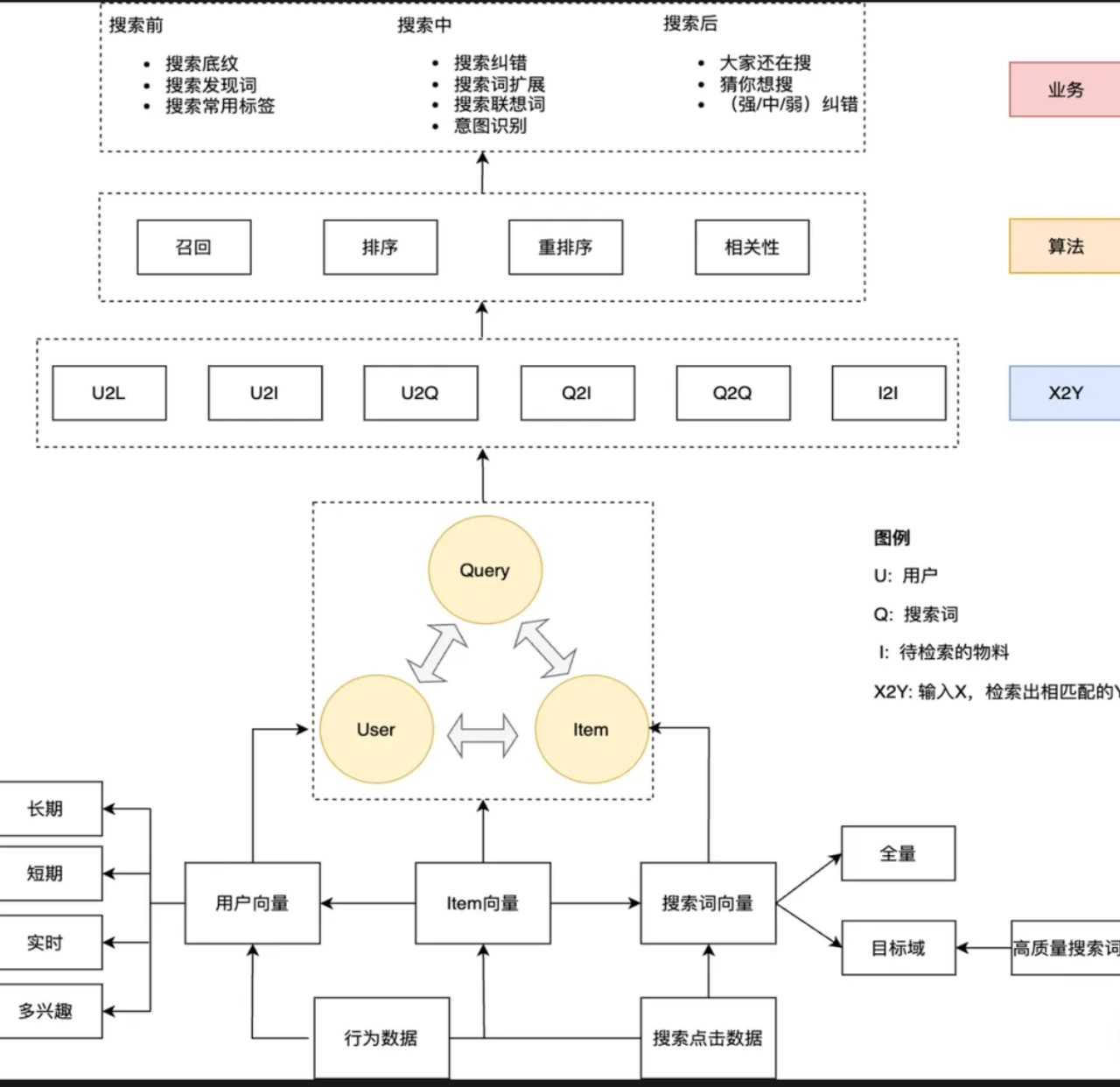
核心模型层 —— X2Y(中间虚线框部分)
这是整个系统最“智能”的部分。图例中解释了 X2Y 的含义:输入 X,检索出匹配的 Y。
这里展示了著名的 “人-货-场” (User-Item-Query) 三角关系
- Q2I (Query to Item): 最经典的搜索。用户搜“手机”,系统找相关的商品。
- U2I (User to Item): 个性化推荐。虽然没搜词,但根据用户画像直接猜他喜欢什么(比如“猜你喜欢”)。
- I2I (Item to Item): 关联推荐。看了这个商品,推荐相似的商品(“看过的还看了”)。
- Q2Q (Query to Query): 搜索词联想/改写。搜了“平果”,系统猜你要找“苹果”;或者搜了“手机”,推荐“手机壳”。
- U2Q (User to Query): 意图预测。根据用户画像,预测他接下来可能想搜什么词。
- U2L / I2I 等: 其他维度的召回路径(L可能指Label标签或List榜单)。
关键点: 这一层正是 Milvus 等向量数据库大显身手的地方。比如 Q2I,就是拿 Query 向量去 Item 向量库里做 ANN 搜索。
这个业务模式说明了为什么我们需要向量数据库:
传统的数据库只能做“文本匹配”(比如 SQL 里的LIKE %keyword%)。而在这个架构中,无论是 U2I(猜你喜欢)还是 Q2Q(语义联想),本质上都是在高维向量空间中计算距离 - Milvus/Qdrant 负责底层的 X2Y 加速(召回层)。
- Elasticsearch 可能负责部分的 文本倒排索引(用于处理某些精确匹配)。
- K8s 则负责调度这整个链路上的各种微服务(排序模型服务、向量检索引擎、前端API等)。
 alipay
alipay
