
正则表达式
正则表达式
https://blog.csdn.net/LLLLQZ/article/details/118278287https://regex101.com/
元字符
普通字符
123abc
反斜杠\
把普通字符转义成特殊用法,具体见下面预定义的字符集
把特殊字符转义成普通输出,像\[\]\{\}\(\)\[\]\?\+\*\.\^\$\|输出就是[]{}()[]?+*.^$|
点运算符 .
.匹配任意单个字符,但不匹配换行符和回车符。
例如,表达式.ar匹配一个任意字符后面跟着是a和r的字符串。
*号
匹配 在*之前的字符出现大于等于0次。
例如,表达式 a* 匹配0或更多个以a开头的字符。表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串。
+号
匹配+号之前的字符出现 >=1 次
?号
在正则表达式中元字符 ? 标记在符号前面的字符为可选,即出现 0 或 1 次。 例如,表达式 [T]?he 匹配字符串 he 和 The。
锚点^号和$号
在正则表达式中,想要匹配指定开头或结尾的字符串就要使用到锚点。^ 指定开头,$ 指定结尾
\b,\B表示单词边界和非单词边界
{}号
在正则表达式中 {} 是一个量词,常用来限定一个或一组字符可以重复出现的次数。
例如, 表达式 [0-9]{2,3} 匹配最少 2 位最多 3 位 09 的数字。我们可以省略第二个参数。 例如,[0-9]{2,} 匹配至少两位 09 的数字。如果逗号也省略掉则表示重复固定的次数。 例如,[0-9]{3} 匹配3位数字
()号
- 将多个字符作为一个整体来处理。如
(ab)+ - 捕获组(Capturing Group)
括号内匹配的内容会被“捕获”,可以在后续的替换或引用中使用。
例如(\d+)-(\d+)
匹配像 “123-456” 这样的字符串,会捕获两个组:
第一个捕获组是 “123”
第二个捕获组是 “456”
你可以在替换时用 $1, $2(某些语言用 \1, \2)来引用它们。
怎么区分捕获还是作整体?
使用非捕获组(?:…)表示只匹配不捕获.比如第一个例子要写成 (?:ab)+
3.命名捕获组
是正则表达式中的一种高级写法,它不仅能捕获匹配的内容,还能给这个捕获组取一个名字,方便在后续代码中引用和使用,尤其适合多个组的情况
(?P<组名>模式)就可以不用$1,$2这种索引名字
(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})
命名捕获组在不同语言中支持方式略有不同:
Python / .NET:用 (?P
JavaScript / Java:用 (?
替换中引用:JS 中可以用 $
字符集[ ]
字符集也叫做字符类。 方括号用来指定一个字符集。
在方括号中的字符集直接列举不关心顺序。 例如,表达式[Tt]he 匹配 the 和 The。(即方括号里是字符的取值范围,这里只能取T,t,如果有字符串che的话则不会被匹配)
在方括号中使用连字符来指定字符集的范围。 [1-9],[a-z],也可以组合使用
[a-zA-Z\d]
字符补集 ^
一般来说 ^ 表示一个字符串的开头,但它用在一个方括号的开头的时候,它表示这个字符集是否定的。 例如,表达式[^c]ar 匹配一个后面跟着ar的除了c的任意字符。
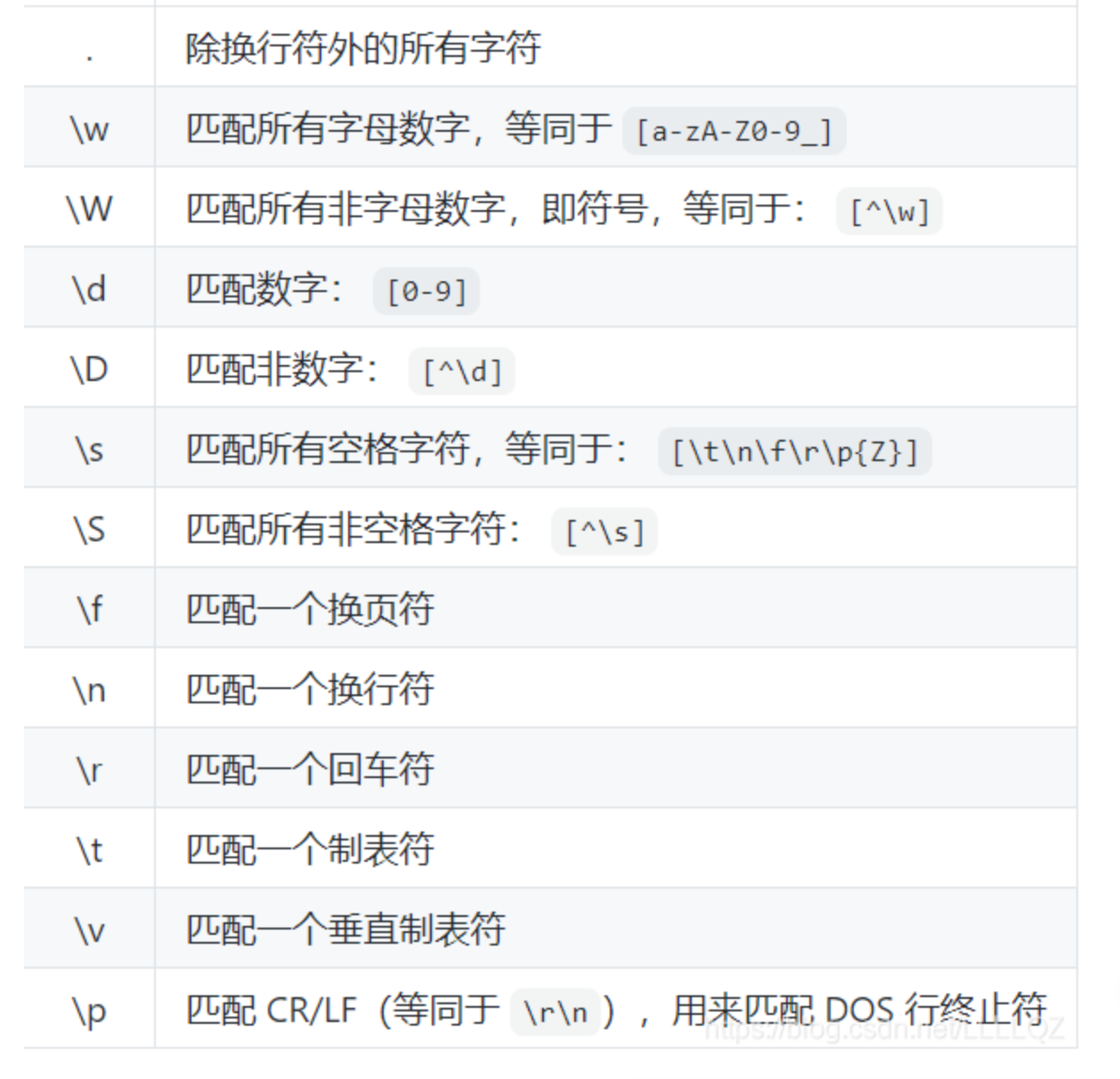
预定义的字符集
逻辑预查
预查(Lookaround)是正则表达式中用来匹配前后环境,但不消耗字符本身的高级技巧。可以把它理解成:“看看前面或后面是不是某个东西,但我不真正匹配它”。
?=… 正向肯定预查
?=… 为正先行断言,表示后面必须跟着 … 才能匹配成功,但不包括在匹配结果里。\d(?=px)匹配 后面跟着 “px” 的数字,只匹配数字本身
?!.. 正向否定预查
后面不能是 … 才能匹配(说白了就是正先行断言的反例)\d(?!px)匹配后面不跟着 “px” 的数字,只匹配数字本身
?<= … 反向肯定预查
前面必须是 …,才能匹配当前位置的字符(?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat,且其前跟着 The 或 the。
?<!.. 反向否定预查
前面不能是 … 才能匹配当前位置
标志
标志也叫模式修正符,因为它可以用来修改表达式的搜索结果。 这些标志可以任意的组合使用,它也是整个正则表达式的一部分。
i忽略大小写g全局搜索m多行修饰符
例如,表达式 /The/gi 表示在全局搜索 The,在后面的 i 将其条件修改为忽略大小写,则变成搜索 the 和 The,g 表示全局搜索,即(不仅仅返回第一个匹配的,而是返回全部)。 例如,表达式 /.(at)/g 表示搜索 任意字符(除了换行)+ at,并返回全部结果(默认)
表达式 /at(.)?$/gm 表示小写字符 a 后跟小写字符 t ,末尾可选除换行符外任意字符。根据 m
修饰符,现在表达式匹配每行的结尾。
贪婪匹配和懒惰匹配
通过在量词后添加 ?,如 *? 或 +?,你告诉正则表达式引擎匹配尽可能少的字符
对于字符串 “aaaaa”:
使用贪婪模式的表达式 a* 会匹配整个字符串 “aaaaa”。
使用非贪婪模式的表达式 a*? 会匹配空字符串,因为 *? 表示匹配尽可能少的字符,包括零个字符。
常用的组合技
.*匹配接下来无限长的任意字符,不包括回车
.*balabala.* 匹配前面随意后面随意中间balabala的字符
[\s\S]表示任意字符
手机号(中国) ^1[3-9]\d{9}$
邮箱地址 ^\[\w.-]+@[\w.-]+\.\w+$
身份证号(简版) ^\d{15}(\d{2}[0-9xX])?$
IP 地址 ^(\d{1,3}\.){3}\d{1,3}$
URL https?\://[\w./?=&%-]+
日期(yyyy-mm-dd) ^\d{4}-\d{2}-\d{2}$
HTML 标签 <[^>]+>
匹配unicode字符的分类和文字脚本
识别字符串中是否包含汉字、阿拉伯字母、日文等特定字符
匹配多语言文本中的特定部分(比如只提取英文或中文)
做国际化处理、Unicode 数据清洗等场景非常实用\p{Category名}\p{sc=Script名}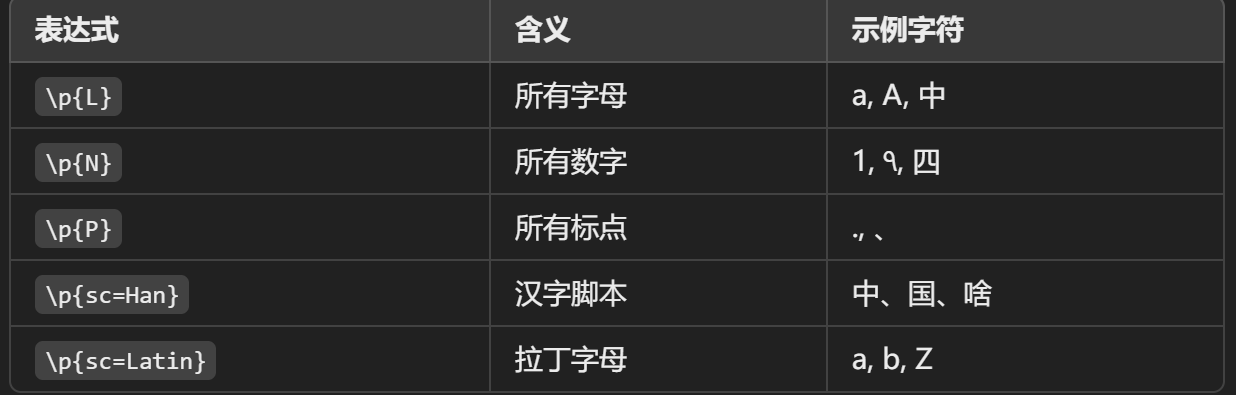
还要更多,看 https://www.regular-expressions.info/unicode.html#category
使用
主要利用捕获组内的内容可以被引用来使用
python
python使用捕获组r"(\d+)" 引用捕获内容r"\1" .group(1)
1 | import re |
字符串还是字符串列表?
re.search() 用 .group(n) 获取re.match() 用 .group(n) 获取re.findall() 返回字符串或元组的列表re.finditer() 返回多个 Match 对象可遍历match.groups() 返回捕获组的元组re.sub() 用 \1 引用组替换
最常用的findall
1 | re.findall(pattern, text_not_covered) 的作用是在字符串 text_not_covered 中查找所有与 pattern (正则表达式模式) 匹配的、非重叠的子字符串。 |
1 | text = "Price: $12.99" |
javascript
创建正则表达式对象
1 | // 方式一:直接字面量 |
构造了函数可以动态输入或者拼接规则.
为什么要动态处理?
关键词来自用户、接口、配置等变量
1
2const keyword = getUserInput(); // 用户输入
const regex = new RegExp(keyword, "i");//i是不关注大小写根本无法预知用户会输入什么,所以没办法事先写死。
关键词是动态组合出来的
1
2
3
4
const filters = ["jpg", "png", "svg"];//扩展名可能来自数据库、配置项、下拉选择……
const pattern = `\\.(${filters.join("|")})$`;
const regex = new RegExp(pattern, "i");静态根本没法覆盖全部可能。
需要动态拼接某段正则规则
比如根据选项拼组合:1
2
3
4
5
6let rule = "^";
if (allowLetters) rule += "a-zA-Z";
if (allowNumbers) rule += "0-9";
rule = `[${rule}]+$`;
const regex = new RegExp(rule);这个就没法靠 /…/ 写死。
用户输入中含有特殊字符,要先处理再用
1
2
3
4
const userInput = "a+b";
const escaped = userInput.replace(/[.*+?^${}()|[\]\\]/g, '\\$&');
const regex = new RegExp(escaped);不可能提前知道用户会输入 a+b、[abc] 还是 .*? 这些,静态写不了。
str.match() 匹配内容 返回字符串 or 数组str.matchAll() 所有匹配 返回迭代器(每个是数组)regex.exec() 执行一次匹配 返回数组(含捕获组)regex.test() 是否匹配 返回布尔值str.replace() 替换匹配项 返回字符串str.split() 用正则分割 返回字符串数组
语法和python差不多,只是返回的一般都是数组,既有全部也有捕获组,还有位置
突然想起来python也可以动态创建正则表达式对象
使用 re.compile() + 字符串拼接
1 | import re |
讲了应该大多数可能会用到的东西
最后推荐网站 https://regex101.com/
 alipay
alipay


